What are Read scale Availability Groups ? (Also referred as Cluster less availability groups many times)
In this blog post let’s see what read scale AGs are and few scenarios when they can be useful for us and how to actually create them. So what exactly is a read scale AG? Well, Microsoft introduced these AGs in SQL 2017 just to serve a single purpose which is to scale our read work loads. These AGs do not offer HA capabilities which we get with a typical AG deployment running on a failover cluster. Since there is no cluster behind the scenes, there is no concept of health checks and hence no automatic failovers. To keep it very simple, consider them as Not Always On AGs 🙂
Well, when can I use Read Scale AGs?
Think of a scenario where all you want is to just isolate your read workload for a given database(s) which doesn’t have any HA requirements and your users and applications are okay connecting directly to your secondary replica for read/reporting work loads, do you really need clustering here? If you are absolutely sure that your AG is not being used for making your database highly available, why to have a cluster and why deal with it?
Note: Read scale AGs do not offer high availability capabilities, This is not for your mission critical database(s) which require HA with automatic failover capabilities. If you have to throw HA in the mix, just stick to traditional AGs.
If not for HA, How about Disaster recovery?
we can certainly get the DR capabilities with Read scale AGs. The reason I say that is, we can have synchronous commit setup which pretty much guarantees the same RPO as a traditional AG would do. Even in a traditional setup when ever I think DR, it’s a manual failover for me….YMMV.
Aaaalright, let’s get into action. I have two standalone SQL Server 2019 Instances joined in the same domain which are not participating in any kind of clustering…you know, just two simple VMs joined to my domain running Windows/SQL, nothing fancy.
First thing first, I enabled AG feature by going to SQL config manager(I did this on both servers), you can see it says “This computer is not participating in a failover cluster”. Duuuh!

I have a database (Not_AO_DB) on which I want to scale my read/reporting work load. well, I went ahead and restored the database manually with norecovery on my second Instance as part of preparing the DB to join in my AG later on.
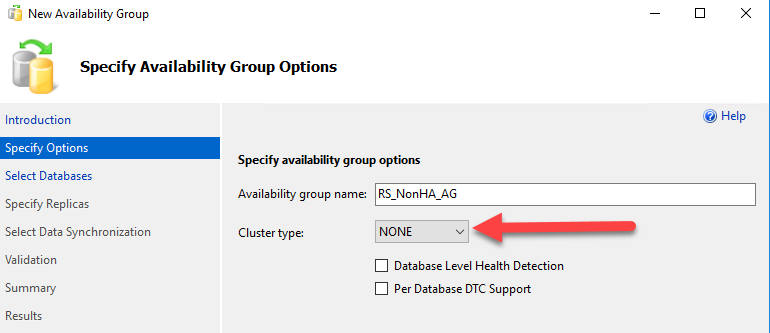
Nothing new so far right, Now….from SSMS, I choose to use AG creation wizard, gave my AG a name and notice the Cluster type selection in below screenshot, that should be NONE.
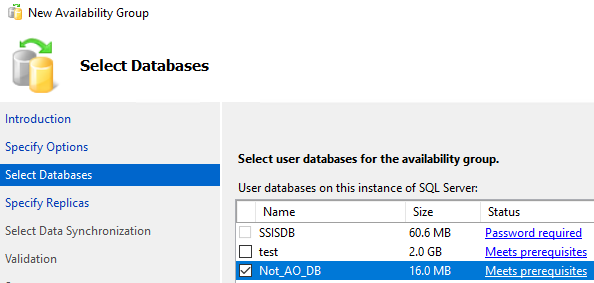
Proceed further and select the database(s) that you want to join in AG, I have “Not_AO_DB” database in my case.
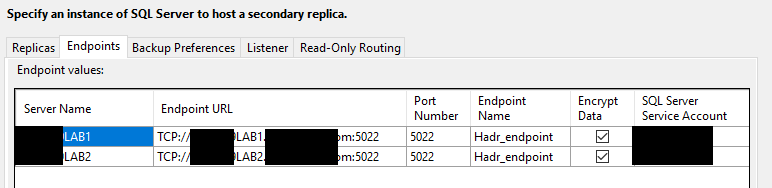
Now notice the highlighted Failover mode, you can see there is only one option(Manual) which can’t be changed(Remember, no clustering means no built in Automatic failover). Set your desired Availability mode to either Synch or Asynch.

It is important to remember, All the good old rules for endpoints like TCP port communication and account permissions etc etc still needs to be in place. The actual SQL Server AG mechanics are same here with read scale AGs.
Time for rules check…Next…Next…Finish!
That’s it folks! That’s pretty much what it takes to create a read scale Availability group. Below is how my dashboard looked like after successful creation of my AG.

In the next post, let’s see how to failover a read scale availability group, Listener GOTCHAS and learn how it is different from a traditional AG.
Happy holidays!


Leave a reply to sreekrishna Cancel reply